操作系统虚拟存储器机制
每当我们安心的使用 LINUX 系统或者在编写 C 语言的时候,安心的使用 malloc 或者 free 的时候,我们很少关注过其底层的内存是怎么工作的,CPU 是如何获取从主存中获取数据的,我们的寻址是不是可以直接寻找到对应的数据,还是通过某种转化机制。实际上,对于每一个进程,它所能接触到的地址都不是实际的物理地址,而是通过虚拟地址进行映射而来的。这里来研究一下虚拟存储器的技术细节。
物理内存和虚拟内存
物理内存
物理内存就是我们电脑上的 RAM 提供的内存。他是固定的,内存条的容量多大,物理内存就有多大(集成显卡系统除外)。但是如果程序运行很多或者程序本身很大的话,就会导致大量的物理内存占用,甚至导致物理内存消耗殆尽。
虚拟内存
简明的说,虚拟内存就是在硬盘上划分一块页面文件,充当内存。当程序在运行时,有一部分资源还没有用上或者同时打开几个程序却只操作其中一个程序时,系统没必要将程序所有的资源都塞在物理内存中,于是,系统将这些暂时不用的资源放在虚拟内存上,等到需要时在调出来用。
值得一提的是,虽然可以直接把物理地址理解成插在机器上那根内存本身,把内存看成一个从 0 字节一直到最大空量逐字节的编号的大数组,然后把这个数组叫做物理地址,但是事实上,这只是一个硬件提供给软件的抽像,内存的寻址方式并不是这样。所以,说它是 “与 地址总线相对应”,是更贴切一些,为了理解方便,这种模型的理解也不算错误。
物理地址与逻辑地址
物理地址 (physical address):用于内存芯片级的单元寻址,与处理器和 CPU 连接的地址总线相对应。它是加载到内存地址寄存器中的地址,内存单元的真正地址。在前端总线上传输的内存地址都是物理内存地址,编号从 0 开始一直到可用物理内存的最高端。这些数字被北桥 (Nortbridge chip) 映射到实际的内存条上。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查 (no translation, no paging, no privilege checks)。
逻辑地址 (logical address):是指由程序产生的与段相关的偏移地址部分。例如,你在进行 C 语言指针 编程 中,可以读取指针变量本身值 (& 操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址,不和绝对物理地址相干。
线性地址 (linear address) 或也叫虚拟地址 (virtual address)
跟逻辑地址类似,它也是一个不真实的地址,如果逻辑地址是对应的硬件平台段式管理转换前地址的话,那么线性地址则对应了硬件页式内存的转换前地址。
为什么需要虚拟地址
- 主存的容量有限。虽然我们现在的主存容量在不断上升,4G,8G,16G 的主存都出现在市面上。但是我们的进程是无限,如果计算机上的每一个进程都独占一块物理存储器 (即物理地址空间)。那么,主存就会很快被用完。但是,实际上,每个进程在不同的时刻都是只会用同一块主存的数据,这就说明了其实只要在进程想要主存数据的时候我们把需要的主存加载上就好,换进换出。针对这样的需求,直接提供一整块主存的物理地址就明显不符合。
- 进程间通信的需求。如果每个进程都 独占一块物理地址,这样就只能通过 socket 这样的手段进行进程通信,但如果进程间能使用同一块物理地址就可以解决这个问题。
- 主存的保护问题。对于主存来说,需要说明这段内存是可读的,可写的,还是可执行的。针对这点,光用物理地址也是很难做到的。
针对物理地址的直接映射的许多弊端,计算机的设计中就采取了一个虚拟化设计,就是虚拟内存。CPU 通过发出虚拟地址,虚拟地址再通过 MMU 翻译成物理地址,最后获得数据,具体的操作如下所示:
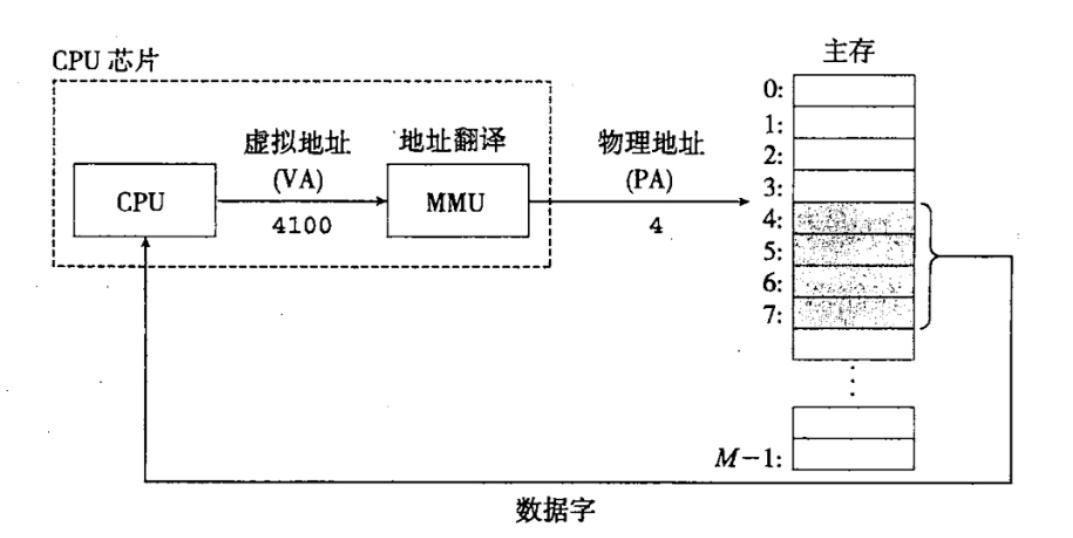
利用了虚拟内存就可以比较有效的解决以上三个问题,在每一个进程开始创建的时候,都会分配一个虚拟存储器(就是一段虚拟地址)然后通过虚拟地址和物理地址的映射来获取真实数据,这样进程就不会直接接触到物理地址,甚至不知道自己调用的那块物理地址的数据。
虚拟地址空间
当处理器读取或写入内存位置时,它会使用虚拟地址。 在读取或写入操作过程中,处理器会将虚拟地址转换为物理地址。 通过虚拟地址访问内存有以下优势:
- 程序可以使用一系列连续的虚拟地址来访问物理内存中不连续的大内存缓冲区。
- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。 当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。 数据或代码页会根据需要在物理内存与磁盘之间移动。
- 不同进程使用的虚拟地址彼此隔离。 一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
进程可用的虚拟地址范围称为该进程的 “虚拟地址空间” 。 每个用户模式进程都有其各自的专用虚拟地址空间。 对于 32 位进程,虚拟地址空间通常为 2 GB,范围从 0x00000000 至 0x7FFFFFFF。 对于 64 位 Windows 上的 64 位进程,虚拟地址空间为 128 TB,范围从 0x000’00000000 至 0x7FFF’FFFFFFFF。 一系列虚拟地址有时称为一系列 “虚拟内存” 。
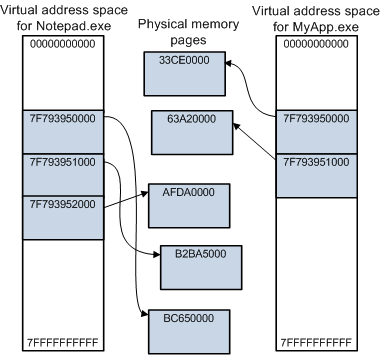
该图显示了两个 64 位进程的虚拟地址空间:Notepad.exe 和 MyApp.exe。 每个进程都有其各自的虚拟地址空间,范围从 0x000’0000000 至 0x7FF’FFFFFFFF。 每个阴影块都表示虚拟内存或物理内存的一个页(大小为 4 KB)。 注意,Notepad 进程使用从 0x7F7’93950000 开始的虚拟地址的三个连续页面。 但虚拟地址的这三个连续页面会映射到物理内存中的非连续页面。 另请注意,两个进程都使用从 0x7F7’93950000 开始的虚拟内存页面,但这些虚拟页面映射到物理内存的不同页面。
地址分页
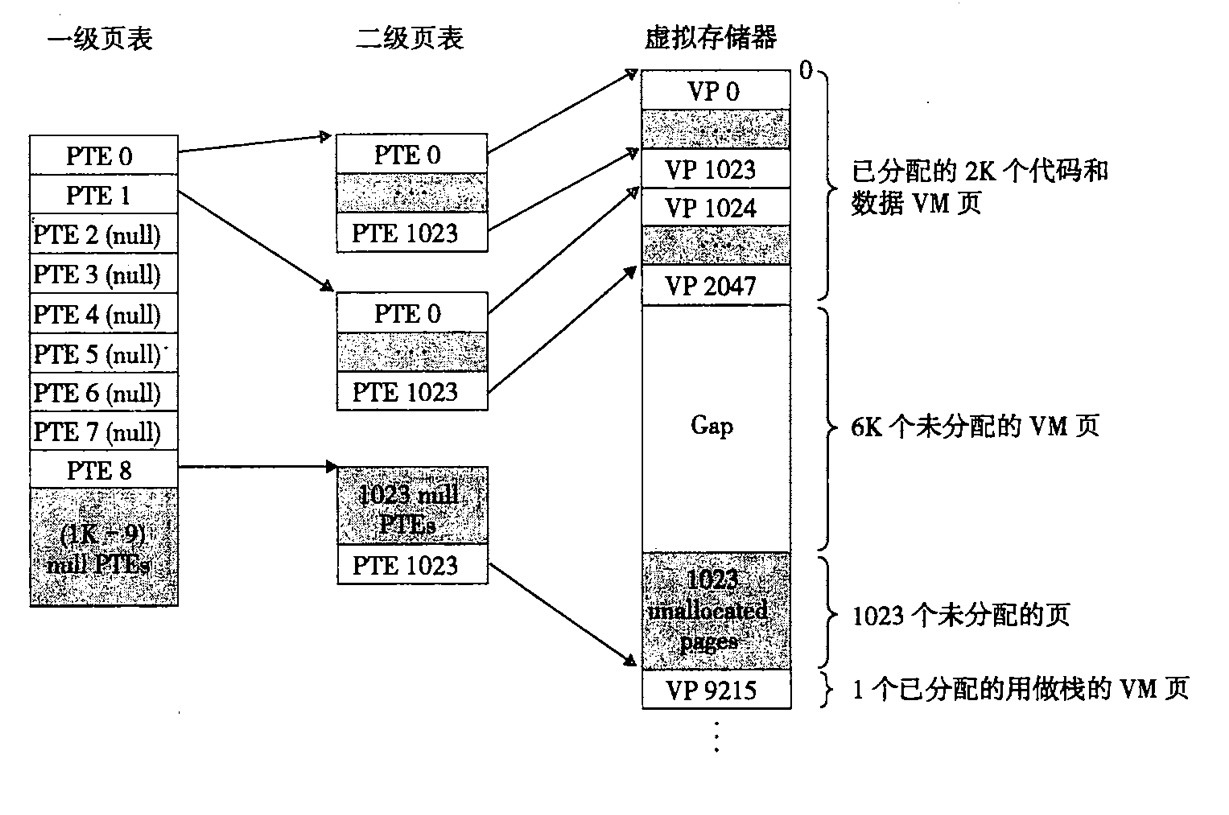
对于一整块连续的内存,直接连续使用也是不太符合实际的。于是,就有分页的概念。将 1024 个地址分成一页,通过访问页来访问数据。那么有了页就要有如何寻找页的概念了。我们通过每一页的首地址作为页入口,即 (PTE) 来检索页。那么,对于这些 PTE,我们也需要一个专门的数据结构来进行管理,这样的数据结构就是页表 (page table)。
虚拟存储器缓存
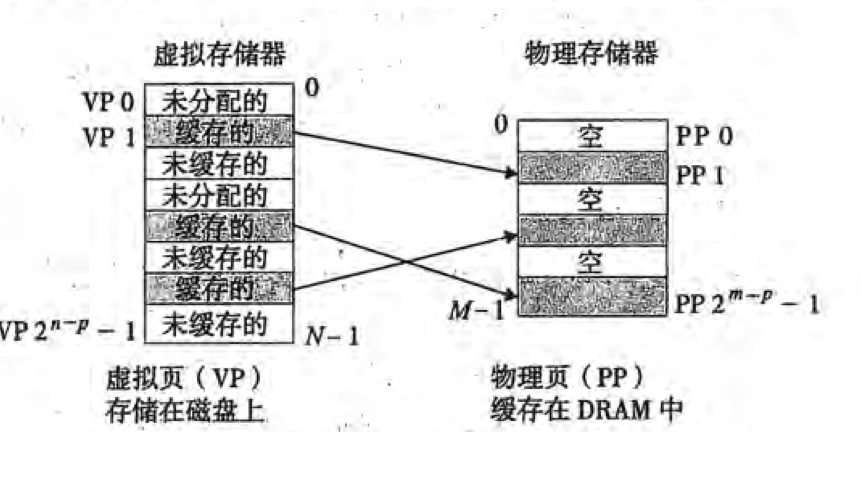
静态随机存储器 (SRAM) 的速度是动态随机存储器(DRAM)的 10 倍,DRAM 是磁盘速度的百来倍,所以 SRAM 常作为 CPU 上 L1,L2,L3 缓存的材料,DRAM 作为主存,针对于 SRAM 和 DRAM,cache MISS 的惩罚而言,DRAM 的惩罚更大,因为 DRAM 的读写速度是磁盘的几百倍,所以利用在 DRAM 的缓存的作用就更大了,针对于虚拟存储器的缓存作用可以用下图所示:
缺页中断
虚拟存储器中的块分为:未分配的,缓存的,未缓存的。
未分配的:顾名思义,这一块的虚拟存储器不映射于任何块。
缓存的:这一块的虚拟存储器映射于已经存在于 DRAM 中的物理页。
未缓存的:这一块的虚拟存储器映射于存在于磁盘中的虚拟页。(也就是要使用就要把磁盘中的虚拟页替换到 DRAM 中的物理页,会发生 Page Fault )
有效和无效通过一个 valid bit (有效位) 来进行判断。
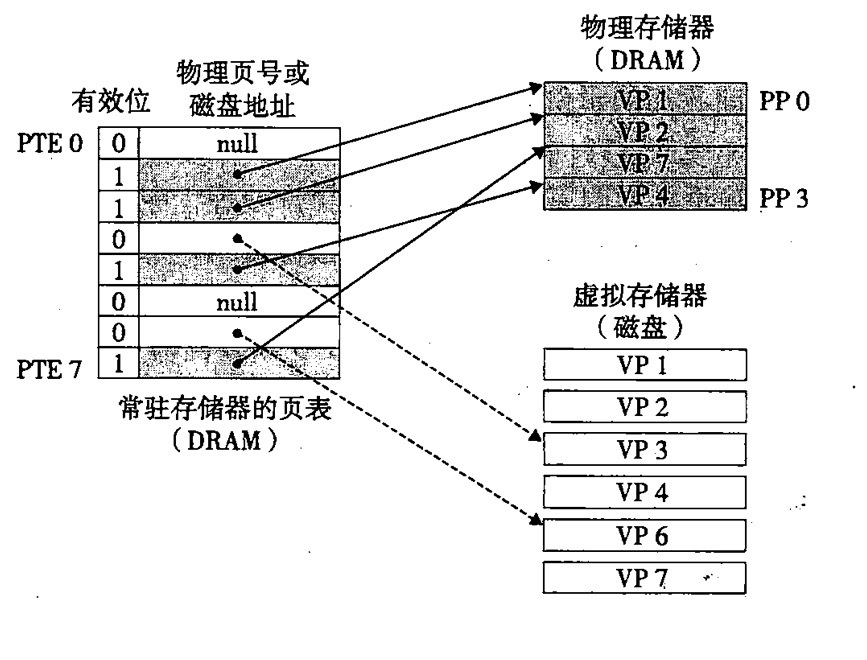
上图中,VM 缺页,对 VP3 中的字的引用不命中,触发缺页。
缺页置换
DRAM 里面有:页表,PTE(页表入口),物理存储器
磁盘里面:虚拟页表
那么对于缓存来说:就有页命中,和页不命中两种情况
页命中:在图中就类似于 VP1,VP2, 这类的页表,直接缓存在 DRAM 中的物理存储器中,可以直接从 DRAM 中获取速度就快了。
页不命中:就是访问页表中未缓存的 PTE,如 VP3,VP6 之类,如下图所说明的情况
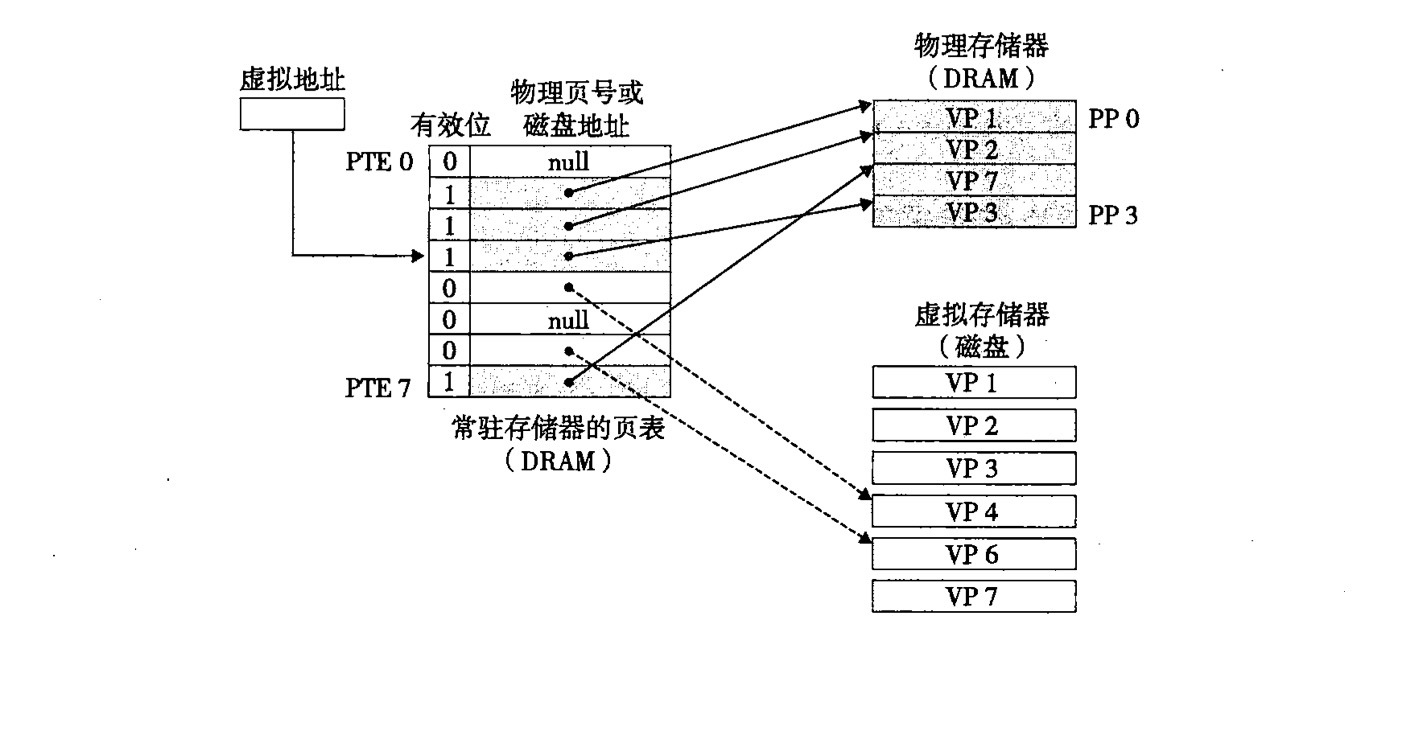
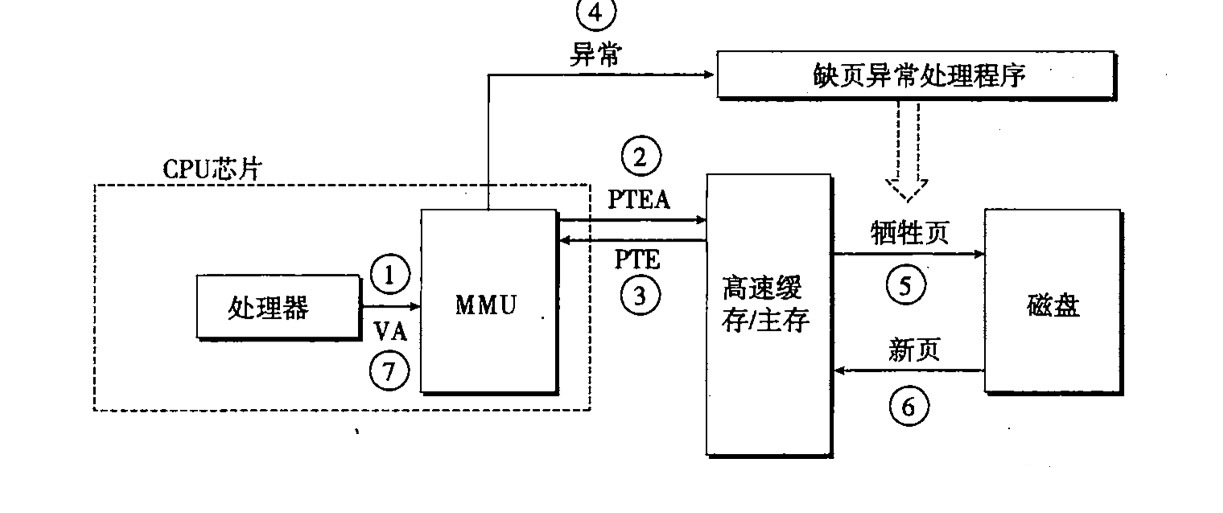
虚拟地址想访问 VP3 的时候,发现 VP3 未在缓存中,发生缺页错误,利用替换算法 (替换算法可能是 FIFO,或者 LRU) 将物理存储器中的一个 VP3 从物理存储器中导出,VP4 从磁盘导入 DRAM 中。此时,PTE3 就变成了已缓存,PTE4 变成了未缓存。这时候在进行地址翻译,就变成页命中了。
可见,缺页错误从磁盘导入的效率是非常低的,但是由于局部性原理,进程往往更多的在较小的活动页面上工作,很少有大跨度的访问内存,使得缺页错误产生的可能性降低。页命中的可能性提高。获取数据的效率就快了很多。
虚拟存储器作用
虚拟存储器的作用有如下几点:
简化共享:利用虚拟地址来映射物理地址,使得可以让多个进程的不同虚拟地址映射同一块物理地址,比如类似于 printf,这一类常用的库,不会把 printf 的代码拷贝到每一个进程,而是让不同进程都使用同一块 printf.
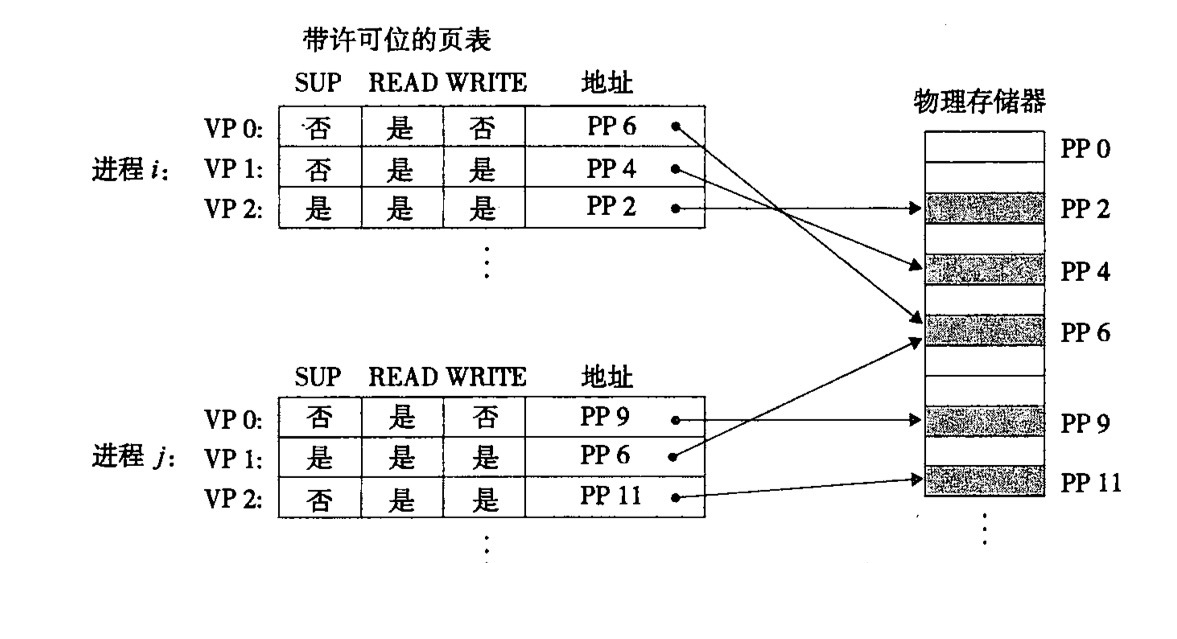
虚拟存储器作为存储器保护的工具,在虚拟存储器里面可以设计该 PTE 是可读,可写,还是可执行的。如果一旦出现只读的 PTE 被写入了,CPU 就会发送出现 segmentation fault (段错误) 但并不会影响到实际存放数据的物理内存,

地址转换
地址翻译的目的是通过 MMU 将虚拟地址翻译成物理地址。
虚拟地址的地址位
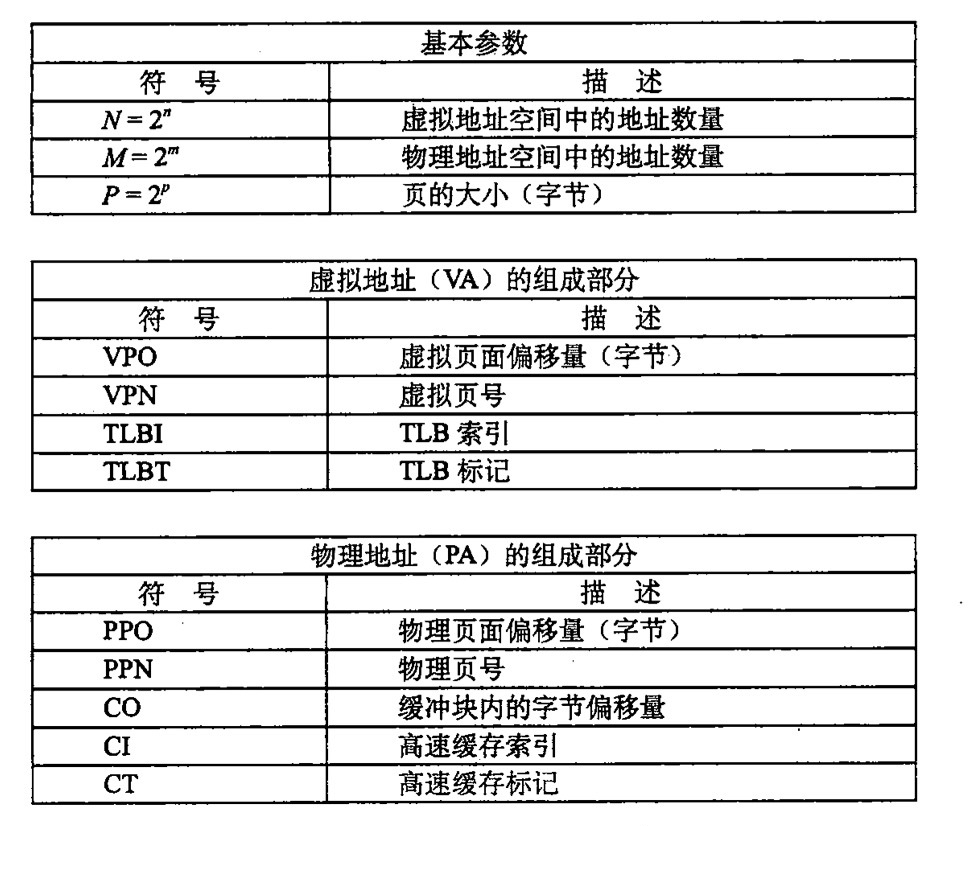
一级页表地址转换
无论是虚拟地址还是物理地址都被分成两个部分,一个页号 (PN),用来寻找对应的存储页,还有一个偏移量 (PO) 用来寻找在对应页中的偏移量。对于偏移量来说,虚拟页的偏移量和物理页的偏移量是相同的。那么,说明我们所需要的转化就是从虚拟页号转化到物理页号。
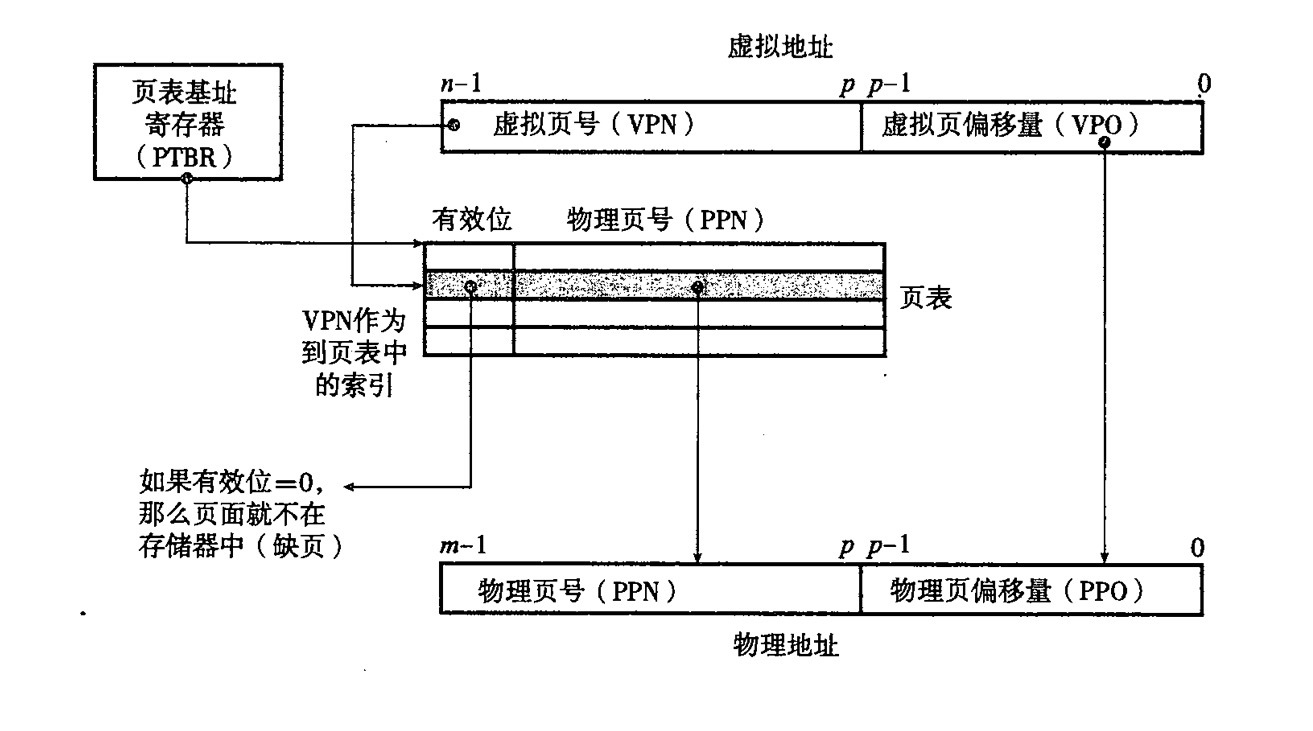
这也就意味着我们可以使用一个小 trick 加速翻译的速度,分别将 VPN,VPO 分开传输,VPN 传输到 MMU 进行翻译,VPO 直接传输到 L1 cache 进行偏移检索,而不是等到 VPN 翻译成 PPN 再进行翻译,这个称作是 优化地址翻译
翻译页号
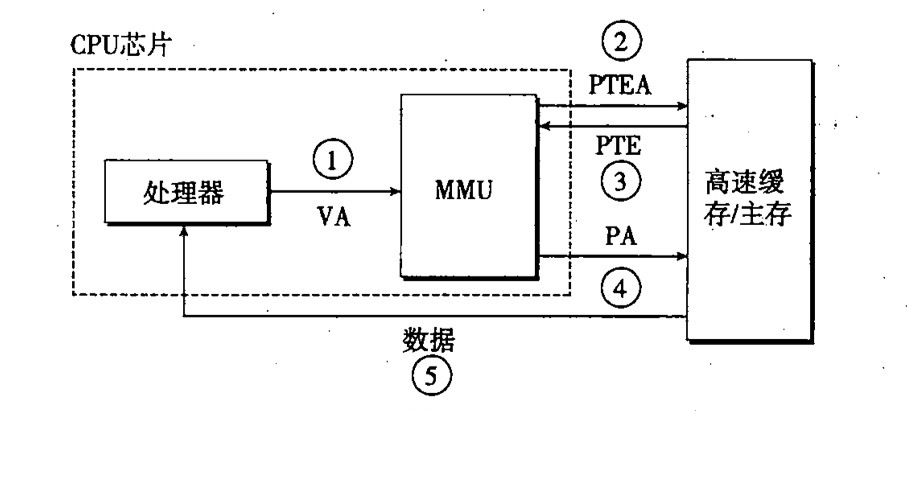
翻译页号的步骤就是通过 VPN 在页表中进行寻找找到对应的 PTE, 如果发现 PTE 的有效位为 0, 说明页面不存在,就出现缺页错误,重新加载页面到物理存储器中,然后设有效位为 1(上面的缺页错误说的就是这个问题)。反之,有效位为 1,说明页命中,取出 PPN 和 VPO 一合,得到物理地址,下图分别说明了,页命中与缺页异常两种情况的翻译情况:
TLB 加速地址翻译
通过 DRAM 中的页表来进行地址翻译的速度有可能太慢了,无法满足速度的需求。这个时候就要 TLB 中派上用场了,TLB 实际位于 CPU 缓存寄存器 Cache 中,作为 SRAM 的一部分,速度是快于页表查询的。TLB 的实际作用,做一个映射,将 VPN 在 TLB 中寻找,找到对应的 PPN。那么问题来了,TLB 是怎么做的映射的呢?这时候就要说明一下 VPN 对于 TLB 来说可以分成那几块,请看下图

可以看见 VPN 被分为 (TLBT:TLB 标记,TLBI:TLB 索引)
这时候再来看看 TLB 构成是什么样的呢?
这里展示的是一个四路组相连的一个 TLB
TLBI 的两位就说明该选 TLB 的那一组,前面的 6 位 TLBT 说明标记位。
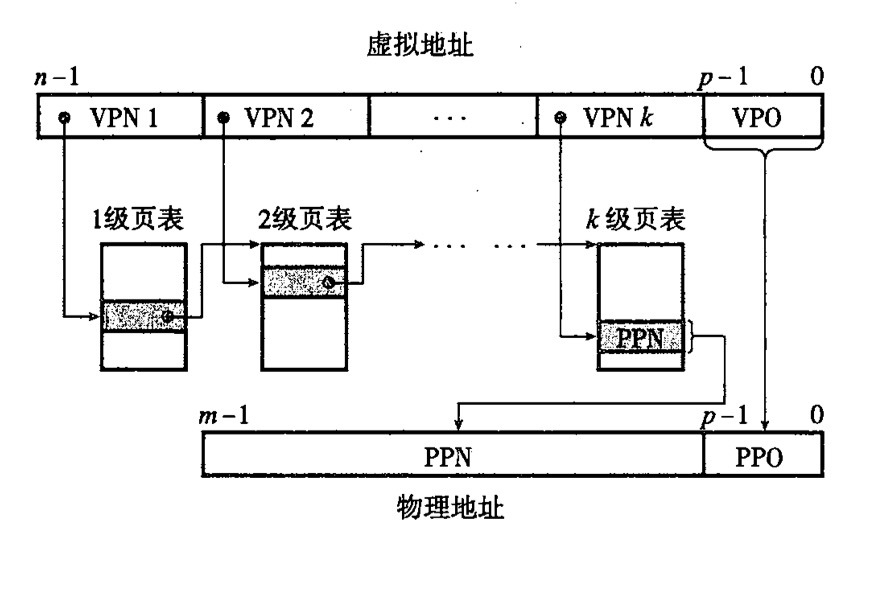
二级和多级页表地址转换
二级页表或者多级页表都是为了更快的检索和更节约空间,请先看下面一个二级页表的例子:
首先二级页表并不复杂,就相当于多了一次映射,我们做一个简单的计算来说明二级页表容量关系,在一级页表中,一个 PTE 指向的是二级页表中,1024 个 PTE 的一页,那么二级页表中的一个 PTE 也就指向虚拟存储器中的一页,也就是 1KB 的地址空间,一个地址中有 32 位,也就是 4 个字节,那么在二级页表中的一个 PTE 所包含的容量就为 4KB 字节。对于一级页表而言,一个 PTE 就代表着 4MB 字节的空间,1K 的一级页表就代表了 4GB 字节的空间,4GB 已经是现在很多内存条的容量了。
那么对于多级页表,一个 VPN 又是怎么分配和映射的呢。相信下面的一张图就可以说明清楚。
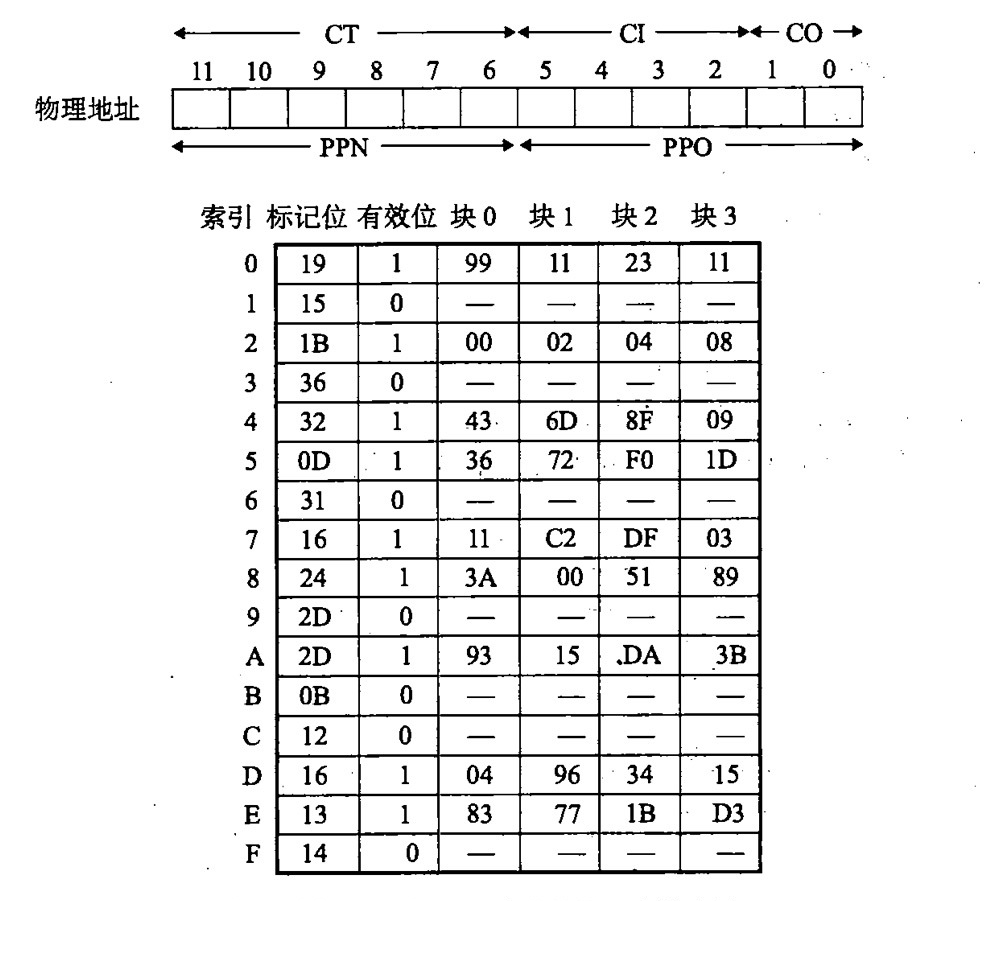
物理地址处理
那么,现在我们得到了物理地址,那么通过物理地址又怎么在物理存储器中寻找到我们想要的数据呢?
先来看一下我们的物理地址分成那几个部分
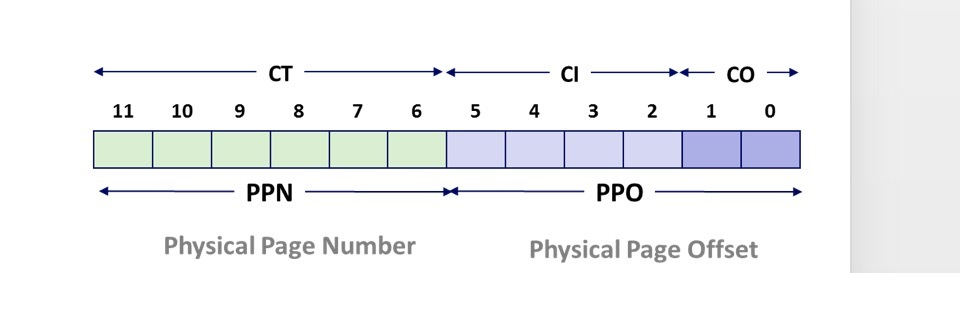
可以看到物理地址被分成了三个部分:CO (块偏移),CI(索引),CT(标签)三个部分
那么物理存储器又长什么样子呢?请看下图:

物理地址先找到 CI 索引,找到对应的 set 集合,然后判断这个集合的 valid bit 是否等于一并且 tag 是否与 CT 一致。如果这些条件都符合,在通过 CO 偏移找到想要的数据。
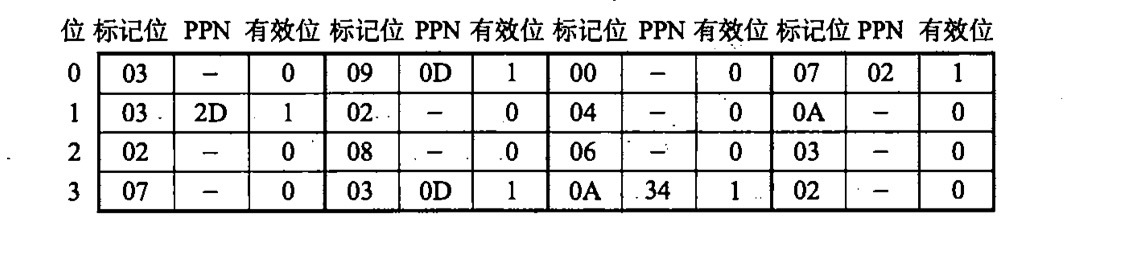
实例
首先,我们的翻译实例是基于一级页表之间的转换,关于虚拟地址以及物理地址的长度及位置如下图所示:

接下来,我们就来实际翻译的虚拟地址。
我们翻译的地址为:0x03d4
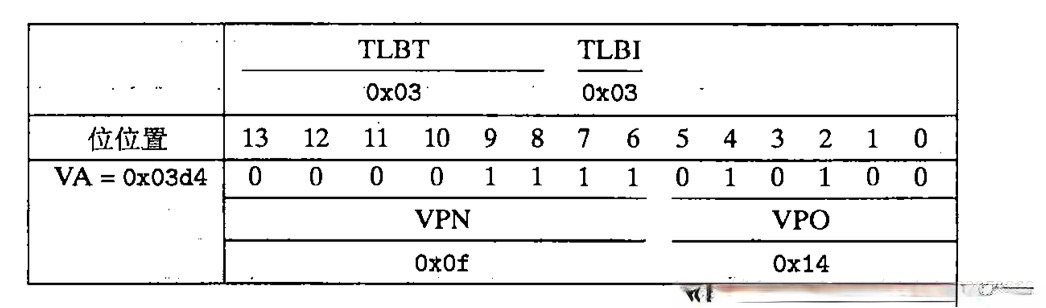
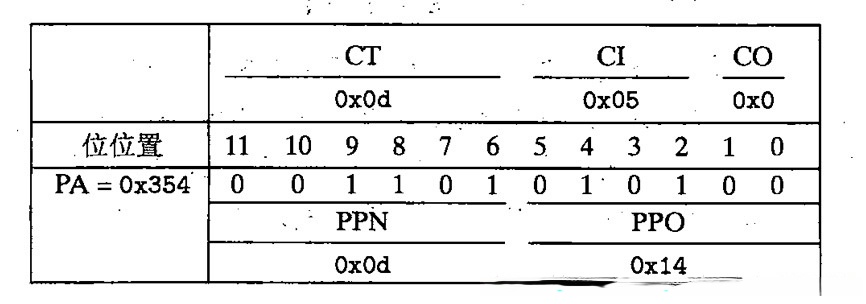
我们得到了 CO=0x0, CI=0x5, CT=0x0d
我们先通过 CI 找索引,然后再通过 CT 对照,很高兴,我们发现标记位相同,都为 0x0D, 且有效位为 1,于是乎我们再通过 CO=0 的偏移,取出了数据 0x36。
这个就是翻译的全过程。