分布式协议之 Raft 算法
Raft 是一种分布式共识算法。相对于之前的 Paxos 协议,它的设计易于理解。它解决了即使面对故障也使多个服务器在共享状态上达成一致的问题。共享状态通常是复制日志支持的数据结构。只要大多数服务器都处于运行状态,我们就需要系统能够完全运行。
Raft 通过选举集群中的一位 leader 来工作。leader 负责接受 client 请求并管理将日志复制到其他服务器。数据仅在一个方向上流动:从 leader 流向其他服务器。
Raft 将共识分解为三个子问题:
leader 选举:如果现有 leader 失败,则需要选举一名新 leader。
日志复制:leader 需要通过复制使所有服务器的日志与其自己的服务器保持同步。
安全性:如果其中一台服务器已在特定索引上提交了日志条目,则其他任何服务器都无法对该索引应用其他日志条目。
基础每个服务器都处于以下三种状态之一:leader,follower 或 candidate。
在正常操作中,只有一个 leader,其他所有服务器都是 follower。follower 是被动的:他们自己不发出请求,而只是响应 leader 和 c ...

WakaTime - 时间记录工具
提高自制力的一个有效的方式就是自我量化,其中一个重要的维度即是时间记录,通过对我们的工作、生活各个方面进行数据记录和分析,可以帮助我们优化自己的时间管理策略,提高生产力。对程序员而言,我们迫切需求有一个工具能够记录我们在工作中的时间分配和利用率。对于项目管理而言,也有了解开发人员开发效率的需求。WakaTime 正是这样一个工具。它专为程序员和开发者而设计,通过简单配置,它就可以记录我们花在各个项目、各种工具 (IDE、浏览器、编辑器等) 以及具体工作内容的时间。对比 Rescuetime 的大而全,Wakatime 专精于记录编程和编辑的方面。推荐开发者都去试试,至少可以帮助提升自制力… :)
。
△ WakaTime 仪表盘
开始使用首先去 WakaTime 注册一个账户。我们也可以用自己的 Github 账户来授权登陆 WakaTime。然后我们需要给我们的 IDE 或者编辑器安装 WakaTime 时间记录插件,目前 WakaTime 已经基本支持主流的 IDE。
安装 IDE 插件我们以 VS Code 和 Chrome 为例,分别给 IDE 和浏览器安装插件。
点击左 ...
分布式系统理论之 CAP 定理
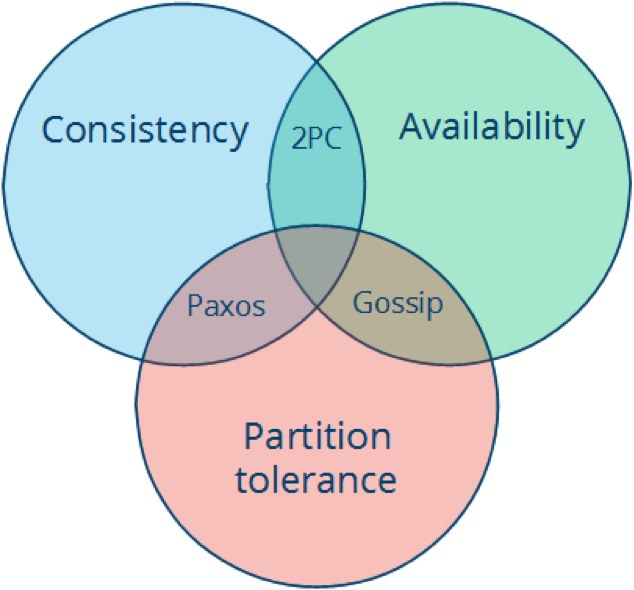
什么是 CAP 定理
CAP 由 Eric Brewer) 在 2000 年 PODC 会议上提出,是 Eric Brewer 在 Inktomi 期间研发搜索引擎、分布式 web 缓存时得出的关于数据一致性 (consistency)、服务可用性 (availability)、分区容错性 (partition-tolerance) 的猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
C 代表 Consistency 一致性, A 代表 Availability 可用性, P 代表 partition-tolerance 分区容错性。
数据一致性 (consistency):如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性 (strong consistency) (又叫 ...

MySQL 面试题详解
总结一波 MySQL 面试题。
数据库基础知识为什么要使用数据库 数据保存在内存
优点: 存取速度快
缺点: 数据不能永久保存
数据保存在文件
优点: 数据永久保存
缺点:1)速度比内存操作慢,频繁的 IO 操作。2)查询数据不方便
数据保存在数据库
1)数据永久保存
2)使用 SQL 语句,查询方便效率高。
3)管理数据方便
什么是 SQL?结构化查询语言 (Structured Query Language) 简称 SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
什么是 MySQL?MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL 是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。在 Java 企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。
数据库三大范式是什么第一范式:每个列都不可以再拆分 ...

Python 的全局解释器锁是什么
全局解释性锁,简称 GIL (Global Interpreter Lock),它是什么,官方有如下解释:
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
我们可以得出:
GIL 在执行 Python 字节码时保护访问 Python 对象而阻止多个线程执行的互斥锁,主要因为 CPython 的解释器非线程安全。
GIL ...

Leetcode 分类刷题指南
一些常见的题型,刷题事半功倍。
1. Pattern: Sliding window,滑动窗口类型经典题目:
Maximum Sum Subarray of Size K (easy)
Smallest Subarray with a given sum (easy)
Longest Substring with K Distinct Characters (medium)
Fruits into Baskets (medium)
No-repeat Substring (hard)
Longest Substring with Same Letters after Replacement (hard)
Longest Subarray with Ones after Replacement (hard)
2. Pattern: two points, 双指针类型经典题目:
Pair with Target Sum (easy)
Remove Duplicates (easy)
Squaring a Sorted Array (easy)
Triplet Sum to Zero (m ...

Linux 之进程调度管理
Linux 内核可以看作一个服务进程 (管理软硬件资源,响应用户进程的种种合理以及不合理的请求)。
这是因为内核需要并行多个执行流,需要防止阻塞。内核线程可以理解为内核的分身,一个分身处理一项特定任务,内核线程调度由内核负责,一个内核线程阻塞不影响其他内核线程, 内核线程是调度的基本单位 。
作为对比,用户线程可以运行在用户态和内核态,内核线程只在内核态。
它只是用大于 PAGE_OFFSET 的地址空间。
Linux 的进程和线程对于 Linux 来讲,所有的线程都当作进程来实现,因为没有单独为线程定义特定的调度算法,也没有单独为线程定义特定的数据结构(所有的线程或进程的核心数据结构都是 task_struct)。
对于一个进程,相当于是它含有一个线程,就是它自身。对于多线程来说,原本的进程称为主线程,它们在一起组成一个线程组。
进程拥有自己的地址空间,所以每个进程都有自己的页表。而线程却没有,只能和其它线程共享某一个地址空间和同一份页表。这个区别的 根本原因 是,在进程 / 线程创建时,因是否拷贝当前进程的地址空间还是共享当前进程的地址空间,而使得指定的参数不同而导致的。
具 ...

K 均值聚类与 python 实现
K-means 算法采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大,是很典型的基于距离的聚类算法。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
步骤算法步骤:
创建 k 个点作为起始支点 (随机选择)
当任意一个簇的分配结果发生改变的时候
对数据集的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据分配到距离其最近的簇
对每一簇,计算簇中所有点的均值并将其均值作为质心
k 个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意 k 个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,J 的值没有发生变化,说明算法已经收敛。
测试数据集首先从 sklearn 导入数据集。我们用非常著名的 iris 数据集。
12345678from sklearn import datasetsfrom matplotlib ...

踩坑记之 zsh 不兼容通配符查找
这是在进行 certbot 通配符 ssl 证书申请时候发生的坑。
123certbot certonly --nginx --preferred-challenges dns --manual -d *.maywzh.com --server https://acme-v02.api.letsencrypt.org/directoryzsh: no matches found: *.maywzh.com
后来发现,在 zsh 下使用 find 命令查找指定目录下所有头文件时也出现问题:
123find . -name *.hno matches found: *.h
后来查看了一些资料才知道,这是由于 zsh 导致的。
具体原因:
因为 zsh 缺省情况下始终自己解释这个 *.h,而不会传递给 find 来解释。
解决办法:
在~/.zshrc 中加入:
1setopt no_nomatch
然后运行
1source ~/.zshrc
然后恢复正常

主定理计算时间复杂度
在算法导论中,主定理可以用来计算递归调用的时间复杂度,在这里给出主定理的证明和几个实例。
主定理描述一个规模为 $n$ 的问题通过分治,得到 $a$ 个规模为 $n/b$ 的问题,每次递归带来的额外计算为 $c (n^d)$,则 $T (n)\leq aT (n/b)+c (n^d)$
问题的复杂度为
T (n)=\begin {equation}
\left\{
\begin {array}{lr}
O (n^d log (n)) & a = b^d \\
O (n^d ) & a < b^d\\
O (n^{log_b^a})) & a > b^d
\end {array}
\right.
\end {equation}证明
可见,每次递归把问题分为 a 个规模为 $n/b$ 的子问题。从根节点开始,共有 $log_b^n+1$ 层,叶子节点数为 $a^{log_b^n}$。那么,第 j 层共有 $a^j$ 个子问题,每个问题规模为 $n/b^ ...